本文共 1224 字,大约阅读时间需要 4 分钟。
本节书摘来异步社区《机器学习与数据科学(基于R的统计学习方法)》一书中的第1章,第1.5节,作者:【美】Daniel D. Gutierrez(古铁雷斯),更多章节内容可以访问云栖社区“异步社区”公众号查看。
1.5 成为一名数据科学家
评估你在机器学习领域的职业规划时,你需要考虑成为一名数据科学家所需要的知识。你只需要查看这一职位最近的招聘公告就能理解这需要多方面的能力。很多公司在寻找在数学、统计建模、算法设计与验证、构建生产系统的软件工程、系统架构和管理、分布式计算机系统(例如:Hadoop和Spark)、云解决方案、存储系统和具有行业经验的候选人。再加上,这个人需要具有和首席高管讨论实验结果的能力。这样的候选人被称为“独角兽”(一种现实中不存在的神兽),或者,根据当前讨论的话题,称之为一名数据科学的超级英雄。事实上,这些职位说明描述了一个团队而不是一个个体,但是很多公司坚持数月甚至超过一年来寻找他们的“独角兽”并不肯妥协。
上面提到的各个领域的数据科学需要截然不同的技能、教育和训练。例如,假设一家公司想在上百万的保险索赔案例中定位异常值来鉴定欺诈,他们会需要一位在抽样和多变量统计分析上有经验的人。这家公司也可能想设计并实现一个软件解决方案为生产系统所用。这两种工作能由一人承担吗?这个人有统计的博士学位,同时也能写代码并且设计/配置硬件架构吗?或者反过来说,要让一个软件工程师做数理统计吗?不太可能——这些职责范围通常是互斥的。
对你来说更现实的是预先确定你想成为一个理论家(theorist)还是实验家(experimentalist)。理论家利用中等大小的数据集(或者从海量数据存储中抽样)执行标准的数据分析、数据清理、探索性数据分析、选择模型并验证,来建立项目的理论基础。这个人应该对机器学习及其背后数学原理有着深刻的理解。另一方面,实验家更多的是一名软件工程师或者在建立生产软件应用方面有经验的人。这个人应该理解机器学习的结构,以及如何把它部署到生产系统中。这个人可以建立Hadoop集群、写MapReduce代码、管理数据存储硬件、写高可用产品代码并处理对可扩展硬件架构的需求。
数据科学定义中包含以上所有特点,这使得雇主和应聘者的生活混乱不清。如果一家公司招聘数据科学家,他们期望找到一个能做复杂统计分析、处理海量数据并设计/建立可扩展软件系统的人吗?很多想要招聘数据科学家的公司确实坚持要找这样的“独角兽”,但是这就像是招聘一个建筑师,不但能设计房子,还需要他倒水泥并干一些钉钉子 的活。
一个解决方案是教育雇主和他们的HR团队:他们真的需要雇佣一个数据科学团队,把“数据科学家”这个职位拆分成专业特长,例如:
数学/统计学;
计算机科学;软件工程;特定领域的经验。图1-3展示的数据科学韦恩图2.0并不是对重叠部分的精确描述,而只是一个形象化的指南。注意到中心的独角兽代表了所有学科的非常稀有的交叉点。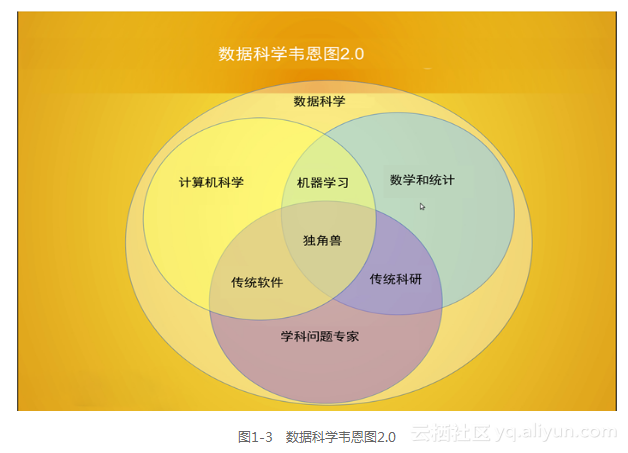
转载地址:http://wpasa.baihongyu.com/